Qwen3 重磅开源!老金揭秘通义千问3:36T数据+思考模式+低成本部署,真香!
家人们!AI圈又地震了!
阿里带着通义千问3(Qwen3)杀回来了!

这次,他们扔了个核弹级的数字:36万亿!
没错!就是训练 Qwen3 用的数据量!36万亿 Token!
这TM是什么概念?!
老规矩,老金带你第一时间扒光它!
看看这葫芦里除了“壕无人性”的数据量,还卖的什么药!
第一炸:36万亿Tokens!迄今已公开数据量最大的 AI 之一
Qwen3直接喂了 36万亿 个token的数据!
36万亿啊!是上一代 Qwen2.5 的两倍!
这是啥概念?
-
整个维基百科加起来,也就几百亿token。
-
世界上最大的图书馆,所有书加起来,可能也就几万亿token。
-
Meta 的 Llama 3 公开说是 15万亿+ token。Qwen3 直接翻倍还多!
-
GPT-4、Claude 3、Gemini 这些大佬不公布具体数字,但普遍猜测也是十几、二十万亿级别。
但别混淆:36 T 是“喂给模型的文字量”(tokens),Qwen 3 最大模型的总参数为 235 B,其中激活参数 22 B,并非 36 T!
说明阿里这次是下了血本,要用知识量碾压对手!
但是!光看量不够! 数据的质量、多样性和训练方法更关键!
阿里也强调了用了高质量数据(甚至用自家多模态模型从PDF提取文本,再用自家LLM优化质量,还用专家模型合成数学和代码数据),加上严谨的训练流程:
-
三阶段预训练:先学广度(>30T数据, 4k上下文)-> 再练深度(+5T知识密集数据)-> 最后加长上下文(高质量长文到32k)。
-
四阶段后训练 (搞混合推理):长思维链冷启动 -> 基于推理的强化学习 -> 思考/非思考模式融合 -> 通用能力强化学习。
好处就是:见多识广! 知识面贼宽,理解贼深!覆盖 119种语言和方言!
中文、英文是强项,其他主要语种也不落下!

第二炸:会“动脑子”的AI?思考模式官方玩法!
除了“吃得多”,Qwen3 还学会了“动脑子”!它搞了个“思考模式”(Thinking Mode)。
-
两种状态自由切换:
-
思考模式 (enable_thinking=True, 默认开启):处理复杂任务(数学、代码、逻辑分析)时,它会像人一样“深思熟虑”,进行多步推理,反复验证,输出更靠谱的结果,甚至会把思考过程用 <think>...</think> 标签给你看!
-
非思考模式 (enable_thinking=False):处理简单任务(快速问答、日常对话)时,它就跳过复杂推理,追求速度和效率,反应飞快!就像 Qwen2.5 那样。
-
怎么控制?超灵活!
-
写代码时 (硬开关):可以通过设置 enable_thinking 参数 (True 或 False) 来指定用哪种模式。官方文档和魔搭社区都有详细的 Transformers 使用示例代码。
-
聊天时 (软开关):更简单!直接在你的问题后面加上 /think (强制深度思考) 或 /no_think (强制快速回答) 就行!模型会听你的,而且只对当前这轮生效!
你:帮我解这道复杂的物理题 /think
Qwen3:(开始深度思考...输出<think>...</think>和答案)
你:今天星期几? /no_think
Qwen3:(快速回答)今天是星期一。
- 部署和本地玩:官方也支持用 sglang (>=0.4.6.post1)、vLLM (>=0.8.4) 这些框架部署,可以开关思考模式(比如 vLLM 用 --enable-reasoning --reasoning-parser deepseek_r1 开启)。本地用 ollama run qwen3:30b-a3b (>=0.6.6) 也能直接开玩!
这个思考模式让 Qwen3 该聪明的时候聪明,该快的时候快,而且控制权在你手里!还能控制“思考预算”!
第三炸:参数和版本,还有省钱黑科技!
光说牛逼不行,得上干货!
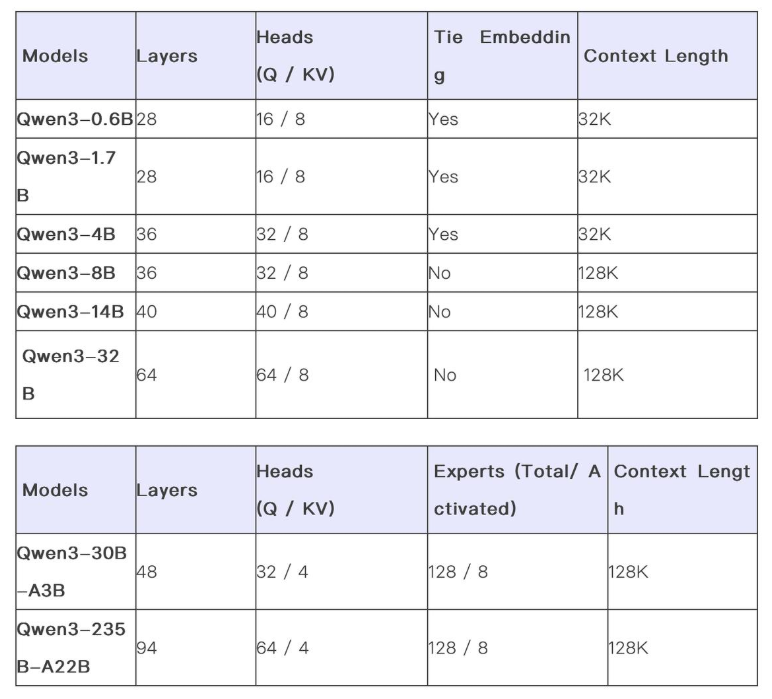
Qwen3 这次搞了个“全家桶”!8款模型全部 Apache 2.0 开源!
-
密集模型 (Dense Models):有小巧玲珑的 0.6B、1.7B,也有主流的 4B、8B、14B,还有更强的 32B 版本。覆盖从手机端(4B)到电脑/汽车端(8B)再到企业大规模部署(32B)的各种场景!
-
混合专家模型 (MoE Models):更炸裂的是 MoE 版!有 30B(但一次只激活 3B 参数,简称 A3B)和 235B(一次激活 22B 参数,简称 A22B)两个版本!这个 "A" 就是 Active(激活)的意思,用更少的计算量跑出大模型的效果,推理更快!官方说 235B 这个版本,显存占用只有性能相近模型的三分之一!省钱就是硬道理!
-
省钱黑科技 (Quantization):魔搭社区上还能找到 FP8 量化版本(比如 Qwen3-30B-A3B-FP8)!啥意思?就是用一种技术把模型“压缩”一下,性能损失很小,但占用的显存更少,跑得更快! 对硬件要求更低,简直是平民玩家和中小企业的福音!
上下文窗口也够大,32k tokens 起步(0.6B/1.7B/4B),大的模型(8B/14B/32B/MoE)更是支持 128k+(通过 YaRN 技术从 32k 扩展)!再长的报告也能一口气读完!
第四炸:硬核数据更新!Qwen3 大战最新顶流!
阿里这次野心不小!号称要设定开源AI新基准!
直接看官方和部分流出数据怎么说!(数据来源参考了官方博客、魔搭社区文章及网上流传的评测图表)
这里能看到老金我一直推荐的Gemini2.5-Pro有多厉害了,各个群里嘴都快说烂的推荐。

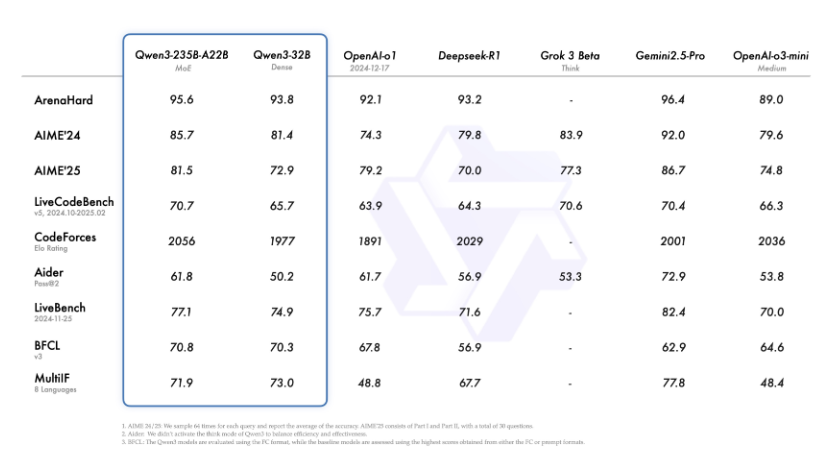
划重点看战绩:
-
旗舰 MoE (235B-A22B) 表现炸裂:
-
在 ArenaHard (人类偏好) 拿了 95.6 分,超过了 OpenAI-o1 (92.1) 和 DeepSeek-R1 (93.2)!
-
在 AIME'25 (奥数级数学推理) 拿到 81.5 分,刷新开源记录!
-
在 LiveCodeBench (代码能力) 突破 70.7 分,甚至超过了 Grok 3 Beta (70.6)!
-
在 BFCL v3 (Agent 工具调用能力) 拿到 70.8 分,超越了 Gemini2.5-Pro (62.9) 和 OpenAI-o1 (67.8)!
-
官方直接说,这个旗舰模型刷新了开源模型的智能水平新高!
-
效率革命!小模型干翻大模型!
-
官方强调 Qwen3 用更小的模型尺寸达到了更大尺寸上一代模型的性能!比如 Qwen3-32B 能跨级超越 Qwen2.5-72B!Qwen3-4B 甚至能匹敌 Qwen2.5-72B-Instruct!
-
30B MoE (激活3B) 性能杠杆超 10 倍,能媲美 Qwen2.5-32B!
-
部署成本大降!
-
旗舰 MoE (235B) 显存占用仅为性能相近模型的三分之一!
-
有报道称,跑满血版 Qwen3 旗舰模型仅需 3-4 张 H20 卡 (约 36-50 万),而跑 DeepSeek R1 可能需要 8-16 张 (约 100-200 万)!成本降低了 65%-75%!
Qwen3 这次不仅性能强悍,能和顶流掰手腕,更在效率和成本上搞事情!
用更少的资源干更多的活,这可能会改变很多 AI 应用的开发和部署格局!
第五炸:官方“外挂”升级!Qwen-Agent 平台与 MCP 支持!
模型牛逼,还得用得爽!官方配套的 Qwen-Agent 框架这次也给了更详细的介绍,而且 Qwen3 原生支持 MCP (模型上下文协议)!
-
Qwen-Agent 干啥的? 就是官方帮你搭好的积木平台,让你用 Qwen3 开发能 自主完成任务的智能体 时,更容易、更快速!
地址:https://github.com/QwenLM/Qwen-Agent/blob/main/README_CN.md
-
核心功能:简化工具调用! Agent 要干活,就得调用各种工具(API)。Qwen-Agent 把调用逻辑、模板、解析器都封装好了。你可以:
-
用 MCP 配置文件 定义工具(Qwen3 原生支持 MCP,Agent 能力更强!)。
-
直接用 Qwen-Agent 内置的工具(比如代码解释器 code_interpreter)。
-
自己集成其他工具。
-
开发者只需要几行代码(官方给了示例),就能配置好模型(比如指定用魔搭上的模型)、工具,让 Agent 跑起来!大大降低了开发门槛!
# 官方 Agent 示例代码概念 (别直接跑,看思路)
from qwen_agent.agents import Assistant
# 1. 配置你的 Qwen3 模型 (用哪个版本,API地址等,可以用魔搭的API)
llm_cfg = {
'model': 'Qwen/Qwen3-32B', # 指定魔搭模型ID
'model_server': 'https://api-inference.modelscope.cn/v1/', # 魔搭API地址
'api_key': '你的ModelScope SDK Token', # 需要去魔搭官网申请
}
# 2. 定义 Agent 能用的工具 (比如查时间、联网搜索、代码解释器,支持MCP)
tools = [ {'mcpServers': {'time': {...}, "fetch": {...}}}, 'code_interpreter' ]
# 3. 创建 Agent 实例
bot = Assistant(llm=llm_cfg, function_list=tools)
# 4. 跑起来!让 Agent 处理你的请求
messages = [{'role': 'user', 'content': '介绍一下 Qwen 的最新进展 https://qwenlm.github.io/blog/'}]
for responses in bot.run(messages=messages):
pass # 处理返回结果
print(responses)
Qwen-Agent + MCP 支持,让 Qwen3 不仅聪明,还能更好地理解和执行复杂任务,连接现实世界!
第六炸:这玩意儿到底能干啥?(使用场景 & 案例)
结合了牛逼的模型、灵活的思考模式、高效的 MoE 架构、方便的 Agent 平台,Qwen3 能干啥?
-
内容创作者:写文章、写剧本、写营销文案,配上“思考模式”,深度内容不是梦!还能生成代码帮你搞网站!
-
打工人:写邮件、写报告、做PPT(结合其他工具)、总结会议纪要、翻译文档(119种语言!),效率神器!
-
开发者:写代码、Debug、解释代码逻辑(LiveCodeBench 高分认证!),利用 Qwen-Agent 快速集成各种 API,开发自动化工具、智能助手,比如:
-
自动客服 + 工单系统:结合知识库 API 和工单系统 API。
-
智能数据分析助手:结合数据库查询 API 和图表生成 API。
-
个性化旅行规划器:结合机票、酒店、天气、地图 API。
-
学生党:解数学题(AIME 高分认证!)、学编程、查资料、练习外语对话,AI私教请一个!
-
企业应用:智能客服、数据分析、市场洞察、自动化流程... 更低的部署成本(尤其是 MoE 和 FP8 版本)和强大的 Agent 能力可能让更多中小企业也能用上强大的、能干活的 AI!
举个栗子:
你想写个复杂点的 Python 程序分析销售数据,直接丢给 Qwen3,加上 “/think”,它就能给你生成靠谱的代码,甚至帮你优化。
你需要快速了解一份几十页的英文财报?丢给 Qwen3,让它用中文总结要点,“/no_think” 模式就够快。
想让AI帮你 自动完成“查询最新产品库存 -> 生成报价单 -> 发送给客户邮箱”这一系列操作?利用 Qwen-Agent 把 Qwen3 和公司的库存系统 API、邮件 API 连接起来,就能实现!
第七炸:哪里可以玩到?魔搭社区是重点!
心动不如行动!现在就可以去这些地方体验和下载 Qwen3:
-
在线体验:
-
Qwen Chat 官网: https://chat.qwen.ai (已可用)
-
通义 APP: (手机端直接体验)
-
夸克 APP: (即将全线接入)
-
模型下载 & API (开发者/企业):
-
魔搭社区 (ModelScope): https://modelscope.cn/models/Qwen (搜索 Qwen3 相关模型)
-
国内首选! 下载模型、找数据集、用官方 EvalScope 评测框架、调用 API(需要 Token)、甚至用 ms-swift 框架进行模型训练和微调,一站式搞定!还能找到 FP8 量化模型!
-
Hugging Face: https://huggingface.co/Qwen (搜索 Qwen3 相关模型)
-
全球通用平台,模型版本也很全。
-
Kaggle: (也是模型托管平台)
-
GitHub: https://github.com/QwenLM/Qwen3 (官方代码、文档和 issue 讨论)
-
阿里云百炼 (Model Studio): https://www.aliyun.com/product/tongyi (官方说即将上线,还会提供 100万 tokens 免费体验!羊毛薅起来!)
-
其他云服务商: Fireworks AI, Hyperbolic 等也提供服务。
-
本地运行工具:
-
Ollama: ollama run qwen3:30b-a3b (简单易用)
-
LMStudio, llama.cpp, MLX-LM (Apple Silicon), KTransformers 等也都支持。

老金怎么看?
一个字:燃!
两个字:想学!
AI这玩意儿,一天一个新花样!
模型越来越强,效率越来越高,成本越来越低,配套工具也越来越完善!特别是魔搭社区,给国内开发者提供了非常好的生态支持!
速度太快了!
感觉脑子快跟不上了!
但越是这样,越不能掉队!
这不仅是技术变革,更是时代赋予我们的新机遇!
去 Qwen Chat 体验!
开发者赶紧去 魔搭社区 / Hugging Face 下载模型!
关注阿里云百炼的免费额度!去试试 Qwen-Agent!
别等到别人都开上AI的“兰博基尼”了,你还在原地踏步!
这个时代,最可怕的不是变化,而是你拒绝变化!