OpenAI全新发布o1(草莓)模型 -人类为王的时间越来越短了?
今天一大早的,草莓模型更新了,直接进入官网可用。

进入老奥的X上看下更新内容。
嗯,PLUS和Team用户可用。
再来看看是干嘛的。
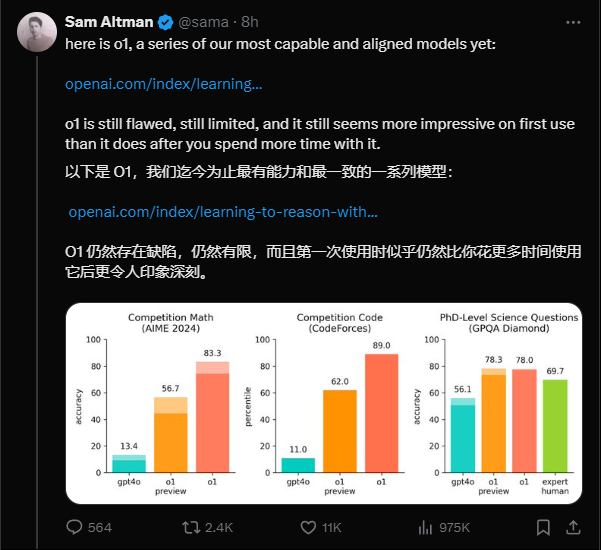
看起来就是个推理更好的模型,那能到什么程度呢?在上面老奥的信息上可以看到一部分。
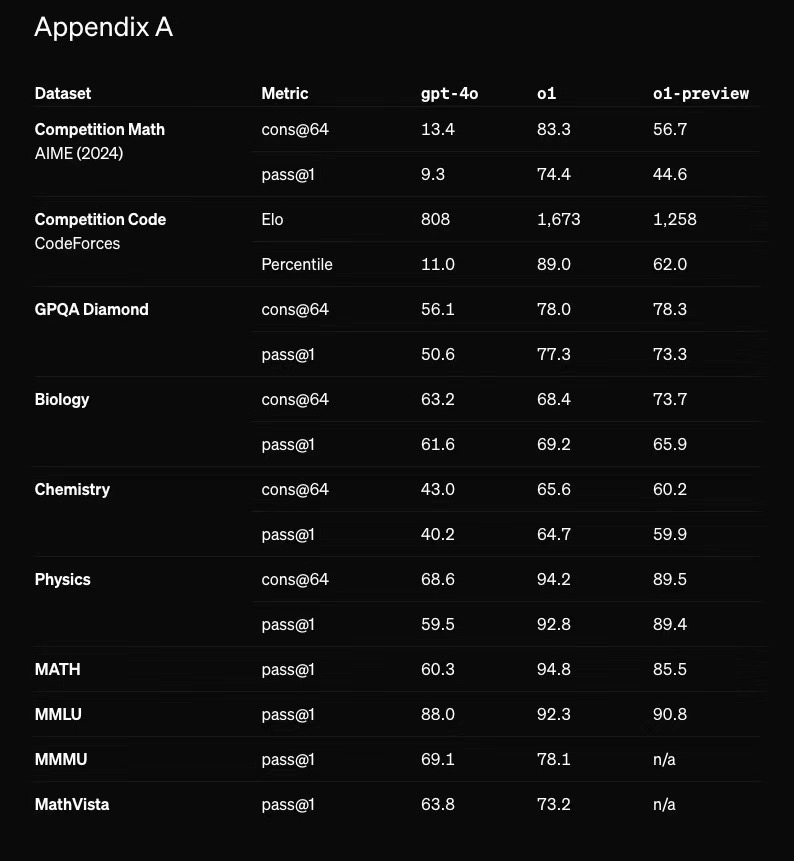
AIME 2024,一个高水平的数学竞赛,GPT4o准确率为13.4%,而这次的o1 预览版,是56.7%,还未发布的o1正式版,是83.3%。
代码竞赛,GPT4o准确率为11.0%,o1 预览版为62%,o1正式版,是89%。
而最牛逼的博士级科学问题 (GPQA Diamond),GPT4o是56.1,人类专家水平是69.7,o1达到了恐怖的78%。
相比来说4o大家应该已经很熟悉了,我一直用的也是4o,就是那个全球出个任意模型都会先说“我们超过了GPT4o”,结果啪啪打脸那个模型。
再看和4o的对比,就能发现o1的恐怖了,而这个模型能达到如此成就,基于的原理是Self-play RL。
又蒙圈了吧,来听老金我给你解释。
自我博弈强化学习(Self-play RL)是一种重要的机器学习方法,通过模拟与自己或多个代理的对战进行学习,提升策略的优化。
就比如,曾经轰动天下的AlphaGo。
它是能通过“自我锻炼”而成长的恐怖模型,它不再需要人类给它提供数据,而是拿自己的数据训练自己。
还蒙圈?没事儿我再提俩赫赫有名的游戏!Dota2和王者荣耀!来看看王者觉悟的设计。

这回明白没明白你为什么连人机都打不过?哈哈,是的,它是一种基于自我学习的AI。
这么强大的模型,目前上线的分为了2种,o1预览版和o1 mini,o1-mini就是更快更小更便宜,推理啥的都不错,极度适合数学和代码,就是世界知识会差很多,适用于需要推理但不需要广泛世界知识的场景。
但是限制也来了,毕竟物以稀为贵,这个使用成本还蛮苛刻的,o1预览版每周30条,o1-mini每周50条。
对于开发者来说,只对已经付过1000美刀的等级5开发者开放,每分钟限制20次。
API价格呢,更是比起现在动辄百万Token1人民币的设定来说,贵了不是一点儿半点儿,即使是mini版本。


老金我作为Chatgpt的深度爱好者,第一时间试了下。
根据OpenAI给出的最佳写法:
-
保持提示简单直接:模型擅长理解和响应简短、清晰的指令,而不需要大量的指导。
-
避免思路链提示:由于这些模型在内部进行推理,因此不需要提示它们“逐步思考”或“解释你的推理”。
-
使用分隔符来提高清晰度:使用三重引号、XML 标签或章节标题等分隔符来清楚地指示输入的不同部分,帮助模型适当地解释不同的部分。
-
限制检索增强生成 (RAG) 中的附加上下文:提供附加上下文或文档时,仅包含最相关的信息,以防止模型过度复杂化其响应。
现看下4o和o1的对比
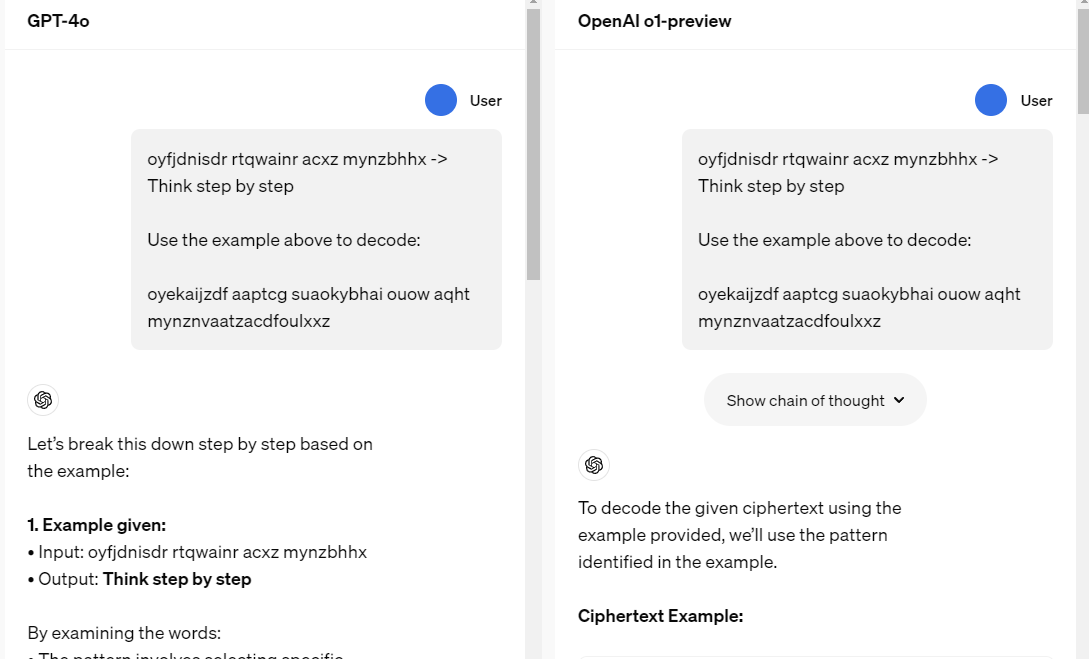
我试了下刚哥这两天爆火的Claude卡片提示词,。
发现了这个不一样的过程,它现进行了自我推理,像不像我们之前写的结构化提示词?也就是它自动进行了CoT(思维链)行为。
并且加入了经典的意图识别。
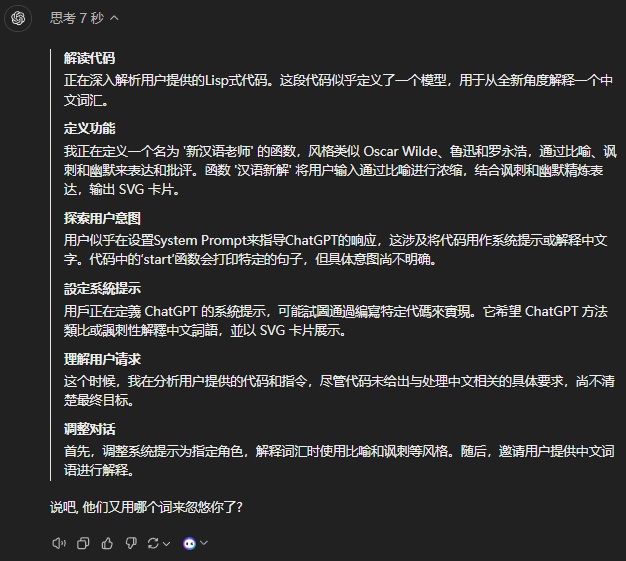
然后我输入了AI俩字,它显示无法生成SVG图片,但是总比之前好了很多,至少它理解了我想做什么,这估计是目前Beta版本的限制,还有很多功能尚未实现,但是推理还是拉满了。
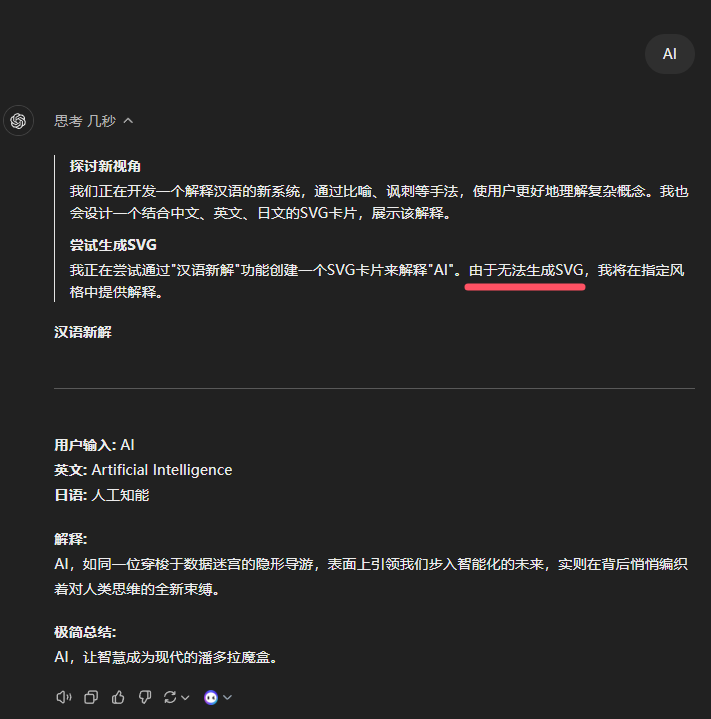
再来看俩经典问题,看起来确实想的很清楚,哈哈哈哈。
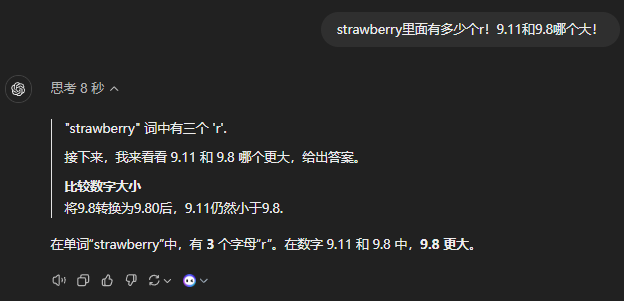
但是在mini中,经过一轮提醒,依然扑街。

再进行个推理问题,我用Preview试了两次,结果是对了1次,错了1次。
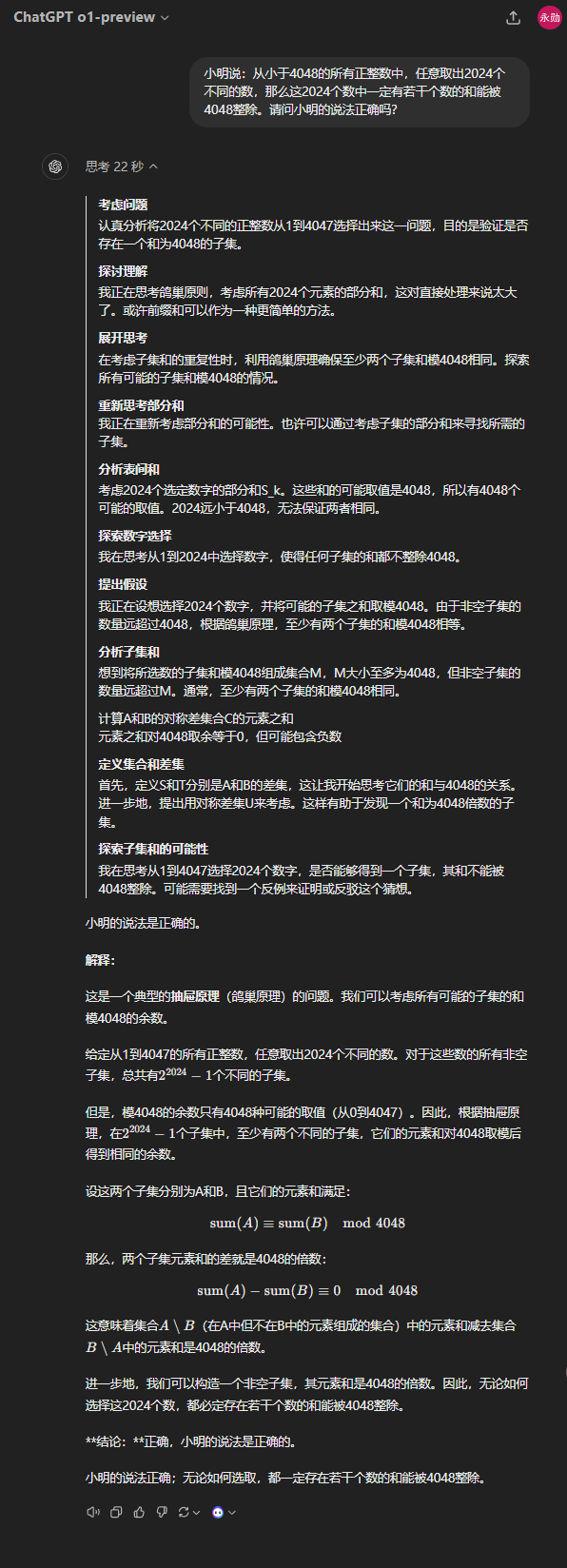

综上总结一下:
新模型加入了COT逻辑,善于进行推理,正确质量远大于4o。
但价格昂贵,且限制数量根本不够用,整体上看起来更像是吴恩达老师说的agentic workflow。

对于质量而言,通过一些案例作证,它还并没有我们想象当中那么强大,但它毕竟还是OpenAI新动作的排头兵,最强大的o1模型还没见到。
综上所述,对于科技进步的期待是要有的,对于他们的答卷也要理性看待,希望大家不要被蒙蔽双眼。
让我们,拭目以待。