Ollama 开源大语言模型部署
大名鼎鼎的Ollama是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型。
Ollma下载地址:https://ollama.com/download
安装使用说明
选择对应系统,直接下载
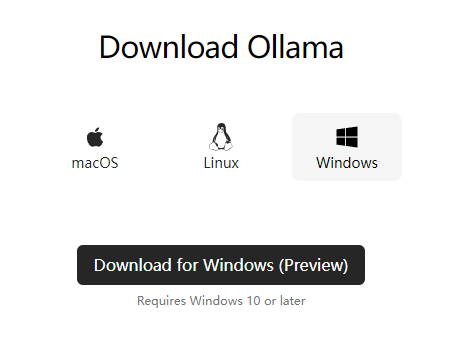
双击直接安装。
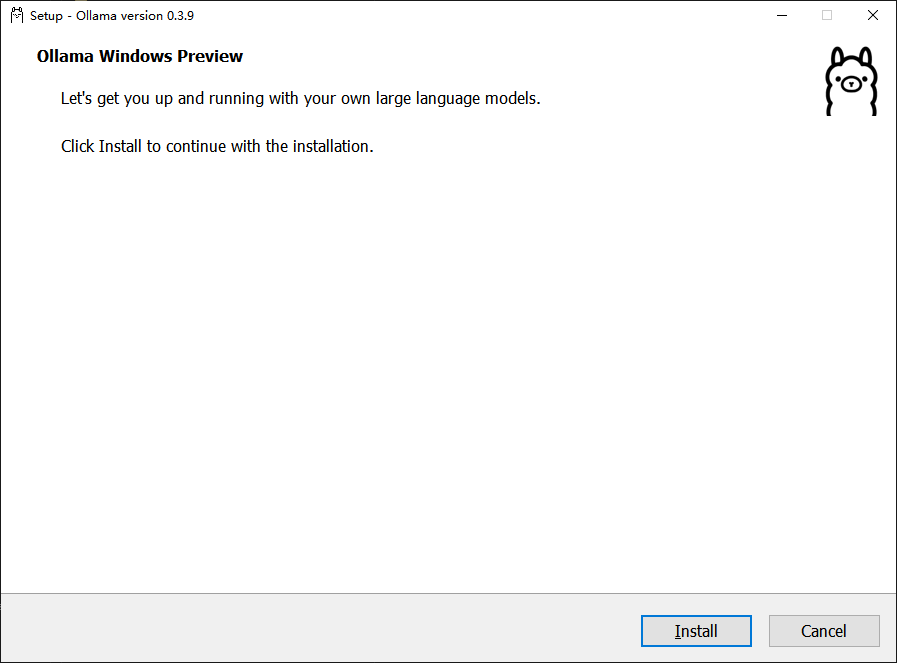
将下方地址复制进浏览器中。如果出现下方字样,表示安装完成。
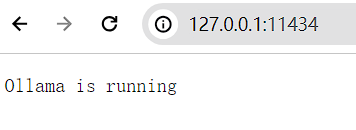
并在系统右下角会出现这个羊驼。

在ollama官网上查看可使用的模型。
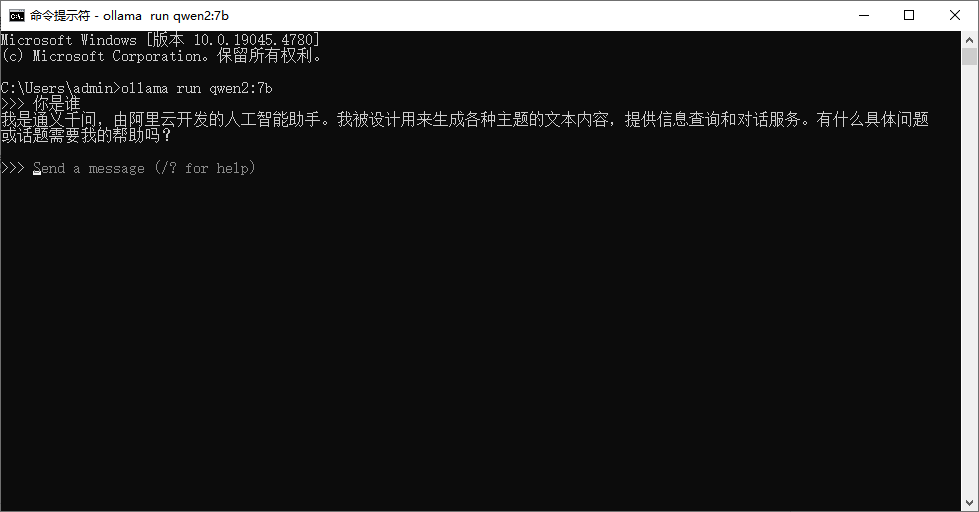
使用win+R打开运行,输入cmd。
这里我选择了qwen2:7b,粘贴以下指令
ollama run qwen2:7b
下载完成,直接输入即可使用。
指令说明
下载模型:
ollama pull model_name
启动模型(若模型不存在,那么会先下载模型,然后再运行):
ollama run model_name
删除模型:
ollama rm model_name
查看下载的模型:
ollama list
查看模型信息 :
ollama show model_name
查看当前运行的模型:
ollama ps
复制模型
ollama cp llama3 model3
运行多模态模型
描述一下图片内容? /d/cloud.jpg
将提示作为参数传入
ollama run qwen "总结文中内容: $(cat README.md)"
列出模型
ollama list
定制自己的模型
所谓定制模型,就是在使用某个模型作为base模型,然后在该模型上进行定制,下面我们就以qwen2:7b作为基础模型进行定制:
1-编写定制规则,即Modelfile文件,内容如下(此处Modelfile位置是C:\Users\Administrator\Desktop):
FROM qwen2:7b
set the temperature to 1 [higher is more creative, lower is more coherent]PARAMETER temperature 1
set the system messageSYSTEM """You are Mario from Super Mario Bros. Answer as Mario, the assistant, only."""
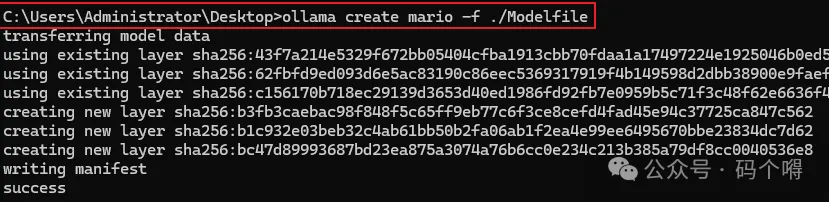
2-使用Modelfile来创建定制模型,执行命令
ollama create mario -f ./Modelfile
3-查看已有的模型,ollama list
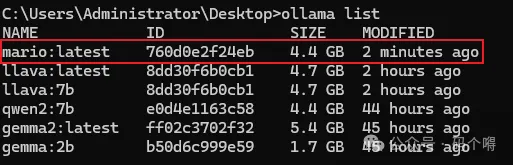
可以看到一个名称为mario 的模型已经存在了。运行该模型,输入prompt试一下:

效果不错,已经能按照定制的内容进行回答问题了。
关于定制化规则,更多的规则可以参考链接:
https://github.com/ollama/ollama/blob/main/docs/modelfile.md
https://blog.csdn.net/spiderwower/article/details/138755776
常见的Q&A整理
如何指定上下文窗口大小
Ollama 默认上下文窗口大小为2048 tokens,可以通过命令 /set parameter num_ctx 4096 将上下文窗口长度调整为4096 token

先运行 gemma:2b模型,然后将上下文窗口长度改为4096
怎么判断模型时运行在CPU还是GPU上的?
执行命令ollama ps,如下图

通过Processor列来判断:
100% GPU 表示模型完全运行在GPU上,即显存中;
100% CPU 表示模型完全运行在RAM,即内存中;
48%/52% CPU/GPU 表示模型即运行在了显存中,也运行在了内存中;
修改Ollama Server的配置
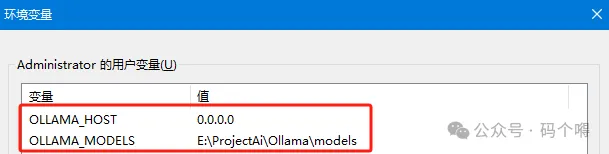
OLLAMA_HOST:修改绑定的地址,可让别人通过局域网访问
OLLAMA_MODELS:修改模型的保存文件夹
更多的Q&A问题,参考官网文档: