GLM-5.2来了,Claude Code百万上下文怎么配?
今儿下午,智谱发布了GLM-5.2。
1M更新了,这个是在Claude code里使用最烦的,这次解决了,因为上个版本为止,它还在一直显示到达条件限制。
今儿老金我试完了,本篇就讲:GLM-5.2这次到底变在哪,1M上下文为什么是重点,用CCSWITCH接Claude Code到底怎么配。
这次真正值得看的是1M上下文
公开报道显示,2026年6月13日,智谱宣布GLM-5.2面向GLM Coding Plan全量用户开放,覆盖Lite、Pro、Max和团队版。报道里还提到,GLM-5.2 API将在下周上线,模型也计划下周正式开源,并遵循MIT协议。
图片加载中…

这几个信息都重要,但老金我会把重点放在1M上下文上。
上下文窗口这个词听起来很技术,简单说就是模型一次能记住多少材料。以前你让AI看一个大项目,它经常看着看着就忘了前面的约定。你让它改一个复杂功能,改到后面它可能把最开始说好的边界弄丢。
1M上下文解决的是长任务里的连续性,因此它的长时间任务也有了大幅的有效提升。
比如你让Claude Code看一个大仓库,前面讲过项目结构、配置规则、历史坑、测试要求,后面又让它修Bug、改文档、查日志。上下文短的时候,它很容易只看眼前那几屏。上下文拉长以后,它至少有机会把前面那些约束一起带着走。
1M上下文不是把整个项目丢进去就撒手不管。它只是让AI更不容易忘,不代表它会自动知道你的目标、取舍和验收标准。模型能记住更多东西以后,反而更需要人把方向卡住。
老金我更愿意这么理解:1M上下文给的是长任务记忆,人还是要负责判断和叫停。
官方配置里最关键的是这个后缀
Z.AI官方Claude Code文档已经给了GLM-5.2的配置方式。
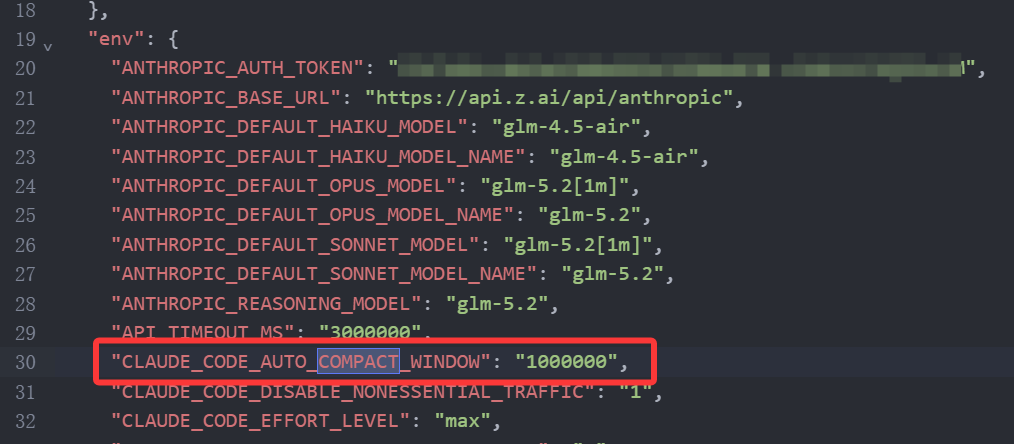
官方文档里还有一个更关键的点:要启用GLM的1M上下文,模型名要加 [1m] 后缀,同时配置压缩窗口。
最小配置长这样:
图片加载中…
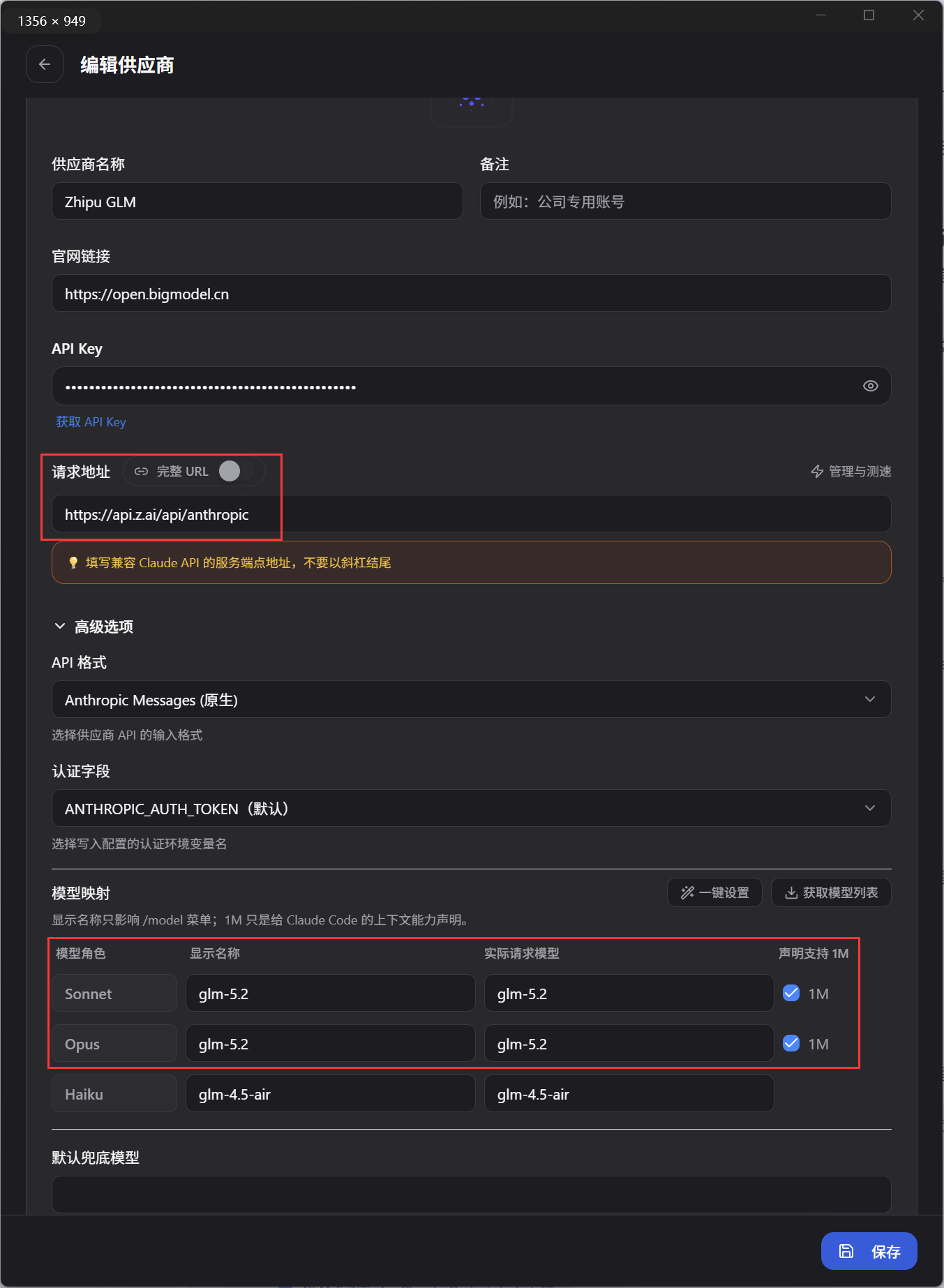
这里最容易错的是两个地方。
第一,glm-5.2[1m] 是实际模型名,不是显示名。你如果在某些工具里又把Claude Code的顶部模型选成 opus[1m],再把实际模型也写成 glm-5.2[1m],就可能看到 glm-5.2[1m][1m] 这种怪东西。
看着像小问题,其实很烦。因为它会让你分不清到底是UI显示叠了,还是模型真的传错了。
第二,CLAUDE_CODE_AUTO_COMPACT_WINDOW=1000000 要一起配。这个就是自动压缩窗口的判断。
官方还提醒,如果Claude Code报带 [1m] 后缀的模型不存在,就先升级Claude Code。这个坑不用硬猜,版本不够就升级。
图片加载中…
WebSearch这块,别再绕远路
这次还有一个很容易被忽略的点。
在老金我这条配置链路里,GLM-5.2跑Claude Code原生WebSearch是通的。Claude Code里直接出现 Web Search(...),能正常完成一次搜索。
这个信息很关键。
因为很多人一看到第三方Anthropic兼容渠道,就本能觉得原生WebSearch可能会400,只能走MCP搜索。
更稳的做法是:
能用原生WebSearch,就优先用原生WebSearch。
原生WebSearch不可见、provider报400、或者你切到的渠道明确不支持,再用MCP兜底。
Z.AI自己也提供了Web Search MCP,工具名叫 webSearchPrime,可以通过Claude MCP命令添加:
claude mcp add -s user -t http web-search-prime https://api.z.ai/api/mcp/web_search_prime/mcp --header "Authorization: Bearer 你的Z.AI API Key"
但这条在我这里应该放在备用位置。原因很简单,Claude Code原生WebSearch更贴近模型自己的决策流程。它什么时候搜、搜几次、怎么把结果塞回回答里,都是Claude Code原生工具链的一部分。
1M上下文应该怎么用
配好以后,别第一时间做那种把整个仓库塞进去的大动作。
我建议先拿一个真实但可控的任务试。
比如你有一个项目,里面有配置文件、命令、几个模块和历史报错。第一轮不要让它直接改代码,先让它读结构:
请先阅读当前项目结构和关键配置,不要修改文件。
输出三件事:
1、这个项目主要做什么。
2、你认为后续修改时最容易踩的3个坑。
3、如果我要让你改一个功能,你建议先给你哪些文件。
这一步是在测试它有没有看懂项目,不是在测试它会不会表演。
第二轮再让它做小改动:
请只改一个最小功能点。
要求:
1、先说你准备改哪些文件。
2、改完后跑最小验证。
3、不要碰无关文件。
4、如果发现需求不清楚,先停下来问。
1M上下文的优势,会在第三轮、第四轮开始出现。它会更容易记得你前面说过的边界,更容易沿着同一个项目语境往下走。
这才是1M上下文的正确打开方式。
不是一次性塞满,而是让长任务少失忆。
然后老金发现它的这个打折活动还在,老金我最近的配置是 Chatgpt20x,Glm年费Pro,Minimax年费Pro,至于Claude,最近没用,因为它现在不上不下的,4.8感觉还不如4.6,新的5今儿也下架了,而且又很贵。
如果你要冲GLM,这里活动是减5%,https://www.bigmodel.cn/glm-coding?ic=FDSW0K6FXM
最后说句人话
老金我现在更愿意把GLM-5.2当成一个信号。
国产模型不只是在追参数和榜单了,它开始进入Claude Code这种真实工具入口,开始接住长任务,开始参与你每天怎么改项目、查资料、验收结果。
这事儿挺值得看。
别只看它能记住100万token。
要看它能不能让你少丢目标、少重复解释、少在配置里绕圈。
这才是今天真正该试的地方。