DeepSeek V3.2来了,首个会"思考"的Agent模型,性能打平GPT-5
昨天晚上刷L站,DeepSeek又发新模型了。
12月1日,V3.2正式版。
看完技术报告,人傻了——首个把"思考"融入工具调用的模型。
性能打平GPT-5,略低于Gemini 3 Pro。
关键是开源,API价格直降50%。
V3.2牛在哪
核心创新:会思考的Agent。
以前模型调工具,直接调。V3.2呢?
先想一遍,再调工具。
举个例子,问它:"帮我查下明天北京天气,顺便订个咖啡。"
普通模型:调天气API→调订单API,完事。
V3.2:
先想"需要查天气和下单,天气影响穿着,可能影响咖啡口味选择"
→调天气API
→根据天气思考咖啡推荐
→调订单API。
多了一层思考,准确率高多了。
技术细节:支持思考模式+非思考模式。
简单任务不思考,复杂任务才思考,省钱。
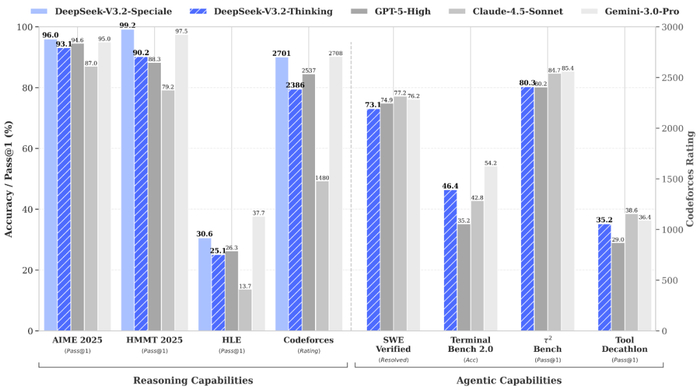
Agent能力暴增
DeepSeek搞了个大规模Agent训练数据合成法。
1800+环境,85000+复杂指令,全是"难回答、易验证"的强化学习任务。
结果:Agent评测达到开源模型最高水平,跟闭源模型差距大幅缩小。
知乎用户测了下,V3.2处理多步骤任务比V3.1强太多。V3.1经常"偷懒",推导十几次就放弃:"由于时间关系,我直接给出常见答案。"
V3.2?一路推到底,不放弃。
Math-V2拿下IMO金牌
11月27日,DeepSeek发了个数学专用模型:DeepSeek-Math-V2。
685B参数,拿下IMO 2025金牌,6道题做对5道,83.3%准确率,全球排第三。
更牛的是Putnam 2024数学竞赛,118分,满分120。
人类历史最高分?90分。
Math-V2直接吊打人类。
技术亮点:验证器优先训练流程。不只看答案对不对,还看推理过程严不严谨。
这是开源数学推理模型首次达到IMO金牌水平。
Speciale版横扫四大竞赛
12月1日,DeepSeek还发了个Speciale版。
这版本专门冲竞赛,拿下四大金牌:
-
IMO 2025(国际数学奥赛)- 金牌
-
CMO 2025(中国数学奥赛)- 金牌
-
ICPC 2025全球总决赛 - 人类第二名水平
-
IOI 2025(国际信息学奥赛)- 人类第十名水平
开源模型首次在这么多顶级竞赛拿金牌。
不过Speciale版有坑:处理复杂任务时token消耗暴增,成本高。适合冲榜,不适合日常用。
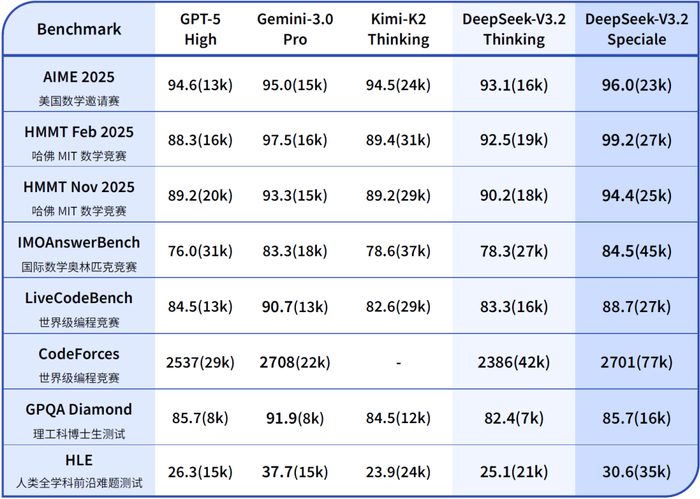
性能对比
跑了AIME 2025数学竞赛测试:
-
V3.2:93.1%
-
GPT-5:94.6%
-
V3.2-Speciale:96.0%
Speciale反超GPT-5了。
编程和命令行任务,V3.2吊打GPT-5。
但Gemini 3 Pro还是老大,大部分类别领先。
DeepSeek官方也承认,三个地方还差点:知识广度、token效率、极复杂任务。
API价格暴降
V3.2 API价格砍了50%以上。
长文本推理场景,成本降50-70%。
算笔账:每天跑100万token,以前$12,现在$6。一个月省$180。
中小团队和个人开发者,这成本太香了。
Speciale版定价跟V3.2一样,但不支持工具调用。
DSA稀疏注意力
V3.2用了DeepSeek Sparse Attention(DSA)。
细粒度稀疏注意力机制,长文本训练推理效率暴增,效果几乎不变。
支持128K上下文长度。
相比Kimi-K2-Thinking,V3.2输出长度大幅降低,计算开销和等待时间都少了。
实测两个月,V3.2-Exp没有在任何场景明显差于V3.1-Terminus。
开源影响
V3.2全开源,技术细节、训练代码、权重全公开,Apache 2.0协议。
Hugging Face上可以直接下载。
开源社区炸了,一堆人在跑微调实验。
这对闭源模型压力大。GPT-5、Gemini 3 Pro虽强,但不开源,价格贵。
V3.2性能接近,还开源,API便宜一半,中小团队肯定选V3.2。
DeepSeek-V3.2 延续了 DeepSeek 的开源传统,模型权重和推理代码已在 Hugging Face 上开源:
适合干啥
玩了一天,总结下:
适合的:
Agent任务 - 多步骤、需要思考的复杂任务,V3.2猛。
数学推理 - Math-V2专攻数学,IMO金牌水平。
编程开发 - 代码生成、调试、重构,比GPT-5强。
成本敏感项目 - API便宜一半,大量调用的项目太香。
中文内容 - 中文理解生成强,写文章翻译对话都行。
不适合:
极复杂任务 - Gemini 3 Pro还是最强,V3.2略差一点。
多模态 - 图片音频视频不支持。
低延迟场景 - 思考模式会增加响应时间。
几个趋势
V3.2对AI圈有几个影响:
Agent能力成标配
"思考+工具调用"这个模式太强了,以后大模型估计都得加。
开源缩小差距
V3.2证明了开源模型能打平GPT-5,闭源优势在缩小。
数学推理突破
Math-V2拿IMO金牌,AI数学能力已经超人类顶尖水平。
成本暴降
API价格降50%,AI门槛又降了,更多人能用上好模型。
国产AI领跑
特别是中文处理、成本控制、Agent能力,已经世界前列了。
最后说两句
玩了一天V3.2,最大感受——AI又进化了。
从"会调工具"到"会思考再调工具",这不是小改进,是质变。
Agent能力起飞,数学推理超人类,API价格降一半。
开源模型跟闭源模型差距在缩小。
AI不再是巨头游戏,是所有人都能玩的竞技场了。
V3.2不是终点。DeepSeek说了,下一步是V4和R2。
未来几个月,肯定还有更猛的东西出来。
参考来源:
-
DeepSeek-V3.2发布,推理能力达到了GPT-5水平 - https://news.qq.com/rain/a/20251201A080EP00
-
DeepSeek V3.2 正式版发布:推理比肩 GPT-5 - https://tech.sina.cn/2025-12-01/detail-infzhxya3047919.d.html
-
DeepSeek-V3.2 发布:开源模型首次达到 GPT-5 水平 - https://stable-learn.com/zh/deepseek-v32-tech-report/
-
DeepSeek V3.2 正式版:强化 Agent 能力,融入思考推理 - https://www.oschina.net/news/386993
-
DeepSeek AI Releases DeepSeekMath-V2 - https://www.marktechpost.com/2025/11/28/deepseek-ai-releases-deepseekmath-v2-the-open-weights-maths-model-that-scored-118-120-on-putnam-2024/
-
DeepSeek-Math-V2 Launches: Open Source Model Conquers IMO - https://news.aibase.com/news/23185
-
DeepSeek-V3.2-Speciale Hugging Face - https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
-
Deepseek V3.2 rivals GPT-5 and Gemini 3 Pro - https://the-decoder.com/deepseek-v3-2-rivals-gpt-5-and-gemini-3-pro-reaches-imo-gold-level-as-open-source/
-
DeepSeek V3.2 用户评价 - https://www.zhihu.com/question/1978819912970555965
-
DeepSeek-V3.2 系列大语言模型发布 - https://www.sysgeek.cn/deepseek-v3-2/